Thank you for the opportunity to complete this challenge! I recently implemented a similar system to ingest our carrier's policies, contacts, and enrollments, so my solution is based on things I learned during and after that process. My code snippets are pretty short and given more time I'd love to show you more error handling, logging, and testing. This document includes my solution, next steps, and answers to the assessment questions.
Assumptions:
- Every broker sends policy, carrier, and client data
- Every broker sends all files at the same time
- Every broker sends their data in force
- Every broker includes the carrier and client foreign key in the policies file
- I've named our broker Mile High Insurance Broker.
- Data sent via sftp, a frontend endpoint, or emailed and manually dropped into a folder in an s3 bucket
- Lambda is triggered when files with a .csv or .xlsx suffix are dropped in the bucket.
# ingest-assets-template.yaml
StateMachineLambda:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub "${ENV}-${project}-StateMachineTrigger"
Handler: main.lambda_handler
...
Events:
EventS3:
Type: S3
Properties:
Bucket:
Ref: S3Bucket
Events: s3:ObjectCreated:*
Filter:
S3Key:
Rules:
- Name: suffix
Value: .csv
...
- Lamda function starts the step functions (state machine).
- Pass information about the event which includes the s3 folder (e.g., s3://highwing_entity_ingestion_prod/mile_high/policies/incoming). This folder shows the broker name and the input type (policies, carriers, and clients).
# main.py
...
def lambda_handler(event: Dict[Any, Any], context: Dict[Any, Any]) -> Dict[Any, Any]:
StateMachineArn = os.environ['StateMachineArn']
client = boto3.client('stepfunctions')
client.start_execution(
stateMachineArn=StateMachineArn,
input=json.dumps(event), # event includes information about the bucket and the object
)
logger.info('State Machine Triggered')
return {'statusCode': 200, 'body': 'State Machine Triggered'}
- The step functions start an ECS task that runs the rest of the entity validator process and waits for a response from the ECS task until it returns an exit code.
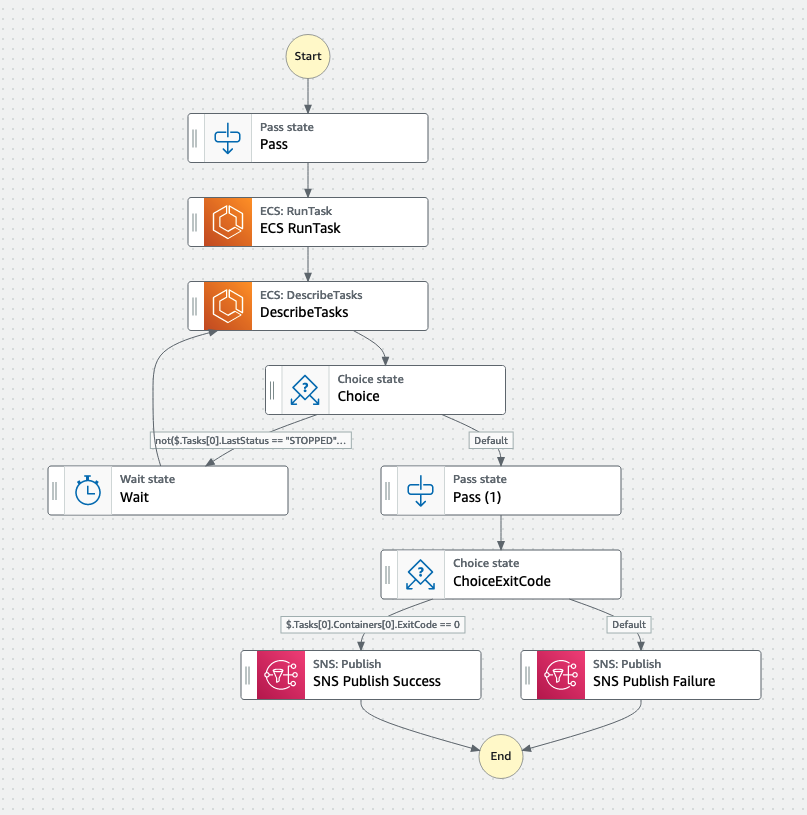
Next Steps: Using an ECS task is the quickest way to get this done. Given more time, I'd like to break the ECS task into a series of lambdas. Breaking down the process can be challenging if you have large datasets. Here's a rough draft:
- Pass
- Get files from s3 and broker entity configurations from DynamoDB (lambda)
- Choice: if files are missing (SQS Publish Failure); if present (Pass)
- Validate file
- Choice file not valid (SQS Publish Failure); if valid (Pass)
- Validate entities, which is the rest of the process (this could be a lambda or ECS task with waiter loop)
- Choice: validity threshold exceeded (SQS publish failure); validity threshold not exceeded (SQS publish success)
- Retrieve the files from s3.
- If policy, carrier, and client files aren't present, SQS publish failure. If all files are present, determine the file type (csv or xlsx).
# ingest_entity.py
...
s3 = boto3.client('s3')
try:
response = s3.get_object(
Bucket=bucket_name,
Key=s3_key,
)
logger.info(f's3 get_object repsonse: {response}')
except ClientError as e:
raise Exception(f'Could not retrieve data file: {s3_key} - original error {e}')
response = s3.get_object(Bucket=bucket_name, Key=file_key)
...
- Retrieve the broker configurations for each entity from the Entity Validator's DynamoDB.
- Validate the data has required fields and values are the correct data type.
{
"broker_key": {
"S": "mile_high"
},
"entity_type": {
"S": "policies"
},
"file_header_map": {
"M": {
"policy_id": {
"S": "Id"
},
"type": {
"S": "Type"
},
"division": {
"S": "Division"
},
"carrier_id": {
"S": "PHONE_NO"
},
"latitude": {
"S": "CarrierId"
},
"client_id": {
"S": "ClientId"
},
...
}
},
"entity_foreign_key": {
"M": {
"carrier_fk": {
"S": "carrier_id"
},
"client_fk": {
"S": "client_id"
}
}
},
"expected_row_count": {
"N": "9"
}
"validity_threshold": {
"N": "6500"
}
}
- Read the files using pandas.
- Validate the data has required fields and values and the correct number of fields. If not valid, SQS publish failure.
policies_df = pd.read_csv(policies_file) # This would be pd.read_excel(policies_file) if this was an excel file
policies_df.name = 'policies'
clients_df = pd.read_csv(clients_file)
clients_df.name = 'clients'
carriers_df = pd.read_csv(carriers_file)
carriers_df.name = 'carriers'
- Change the dataframe (broker) headers to Highwing's headers.
for df in [policies_df, clients_df, carriers_df]:
for highwing_header, broker_header in broker_configs[df.name]['file_header_map'].items():
df.rename(columns={broker_header:highwing_header}, inplace=True)
- Add row number fields, so the validation errors will appear the same order as the original file.
policies_df['policies_row_num'] = policies_df.index
clients_df['clients_row_num'] = clients_df.index
carriers_df['cariers_row_num'] = carriers_df.index
- Use Pydantic to validate each input type.
- These code snippets don't include all the validations I would include (see part 1, question 1 for further details).
- The Policy Pydantic model is the parent class that includes validations for every policy from every broker. MileHighPolicy is the child class and includes validations for every policy from Mile High Insurance Broker. The parent class allows consistency for things like expiration_date (i.e., this field is required for every broker, and we reformat it to datetime). The child classes allow for flexibility (i.e., some brokers include their foreign key in their policies file, and some include their policy foreign key in their other files).
# policy.py
...
class Policy(BaseModel):
id: int
carrier_id: int
client_id: int
duplicate: bool # return a validation error if there's two policies with this id in the file
type: str
effective_date: Optional[datetime] = None # fields can be optional
expiration_date: datetime
written_premium: Union[float, int] # accepts more than one field type
class Config:
# Special inner class used by pydantic to configure model behavior
allow_mutation = False
extra = Extra.allow
...
# mile_high_policy.py
...
BROKER_DIVISIONS = ["Phoenix", "Chicago", "Seattle", "Denver"] # could also be stored in the broker's entity dynamodb table
class MileHighPolicy(Policy):
carrier: bool # return a validation error if there's no carrier with that id in the carriers file
clinet: bool # return a validation error if there's no client with that id in the clients file
division: str
carrier_policy_no: Optional[int] = None
@validator('division')
def validate_division(cls: Type[OP], division: Optional[str]) -> Optional[str]:
if division.capitalize() not in BROKER_DIVISIONS:
raise ValueError(f'{division} not in approved divsisions for this broker {BROKER_DIVISIONS}.')
return division.capitalize()
@validator('extras')
def extras_to_json(cls: Type[OP], extras: Dict[str, Any]) -> str:
# Store extra info the broker gives you in the csv file
...
-
Until the validity threshold for any entity type is met, loop through policies df
Validity conditions:- policy is valid (use Pydantic to validate)
- policy_id is unique (use pandas is_unique)
- associated carrier is valid (use pandas to get row and Pydantic to validate)
- associated client is valid (use pandas to get row and Pydantic to validate)
If all validity conditions are met:
- add them to their respective valid sets
- remove associated carrier and client from their DataFrames
If not all validity conditions are met:
- send to a ValidationError class to format the error and add them to their respective invalid sets
- remove associated carrier and client from their DataFrames
- Loop through carrier and client DataFrames which now contains orphans
- validate them
- send to a ValidationError class
- and add them to the invalid entity set
- Match the entity with its corresponding entities.
- Make {entity_type}_validation_errors csv files. These files include valid and invalid entities in the same order they were received.

- Upload the raw data file and the validation errors to s3 /successful (if invalid entities < validity threshold) or /failed (if invalid entities < validity threshold)
- Entity validator sends a message to the
Brokersaying that process is complete. TheMain Service(I wouldn't name it Main Service) is subscribed to that topic.
- The
Ledgeris subscribed to all the topics in this process. This service is a register of events that happened and stores enough metadata about those events to be useful. I could help generate ingestion and billing reports.
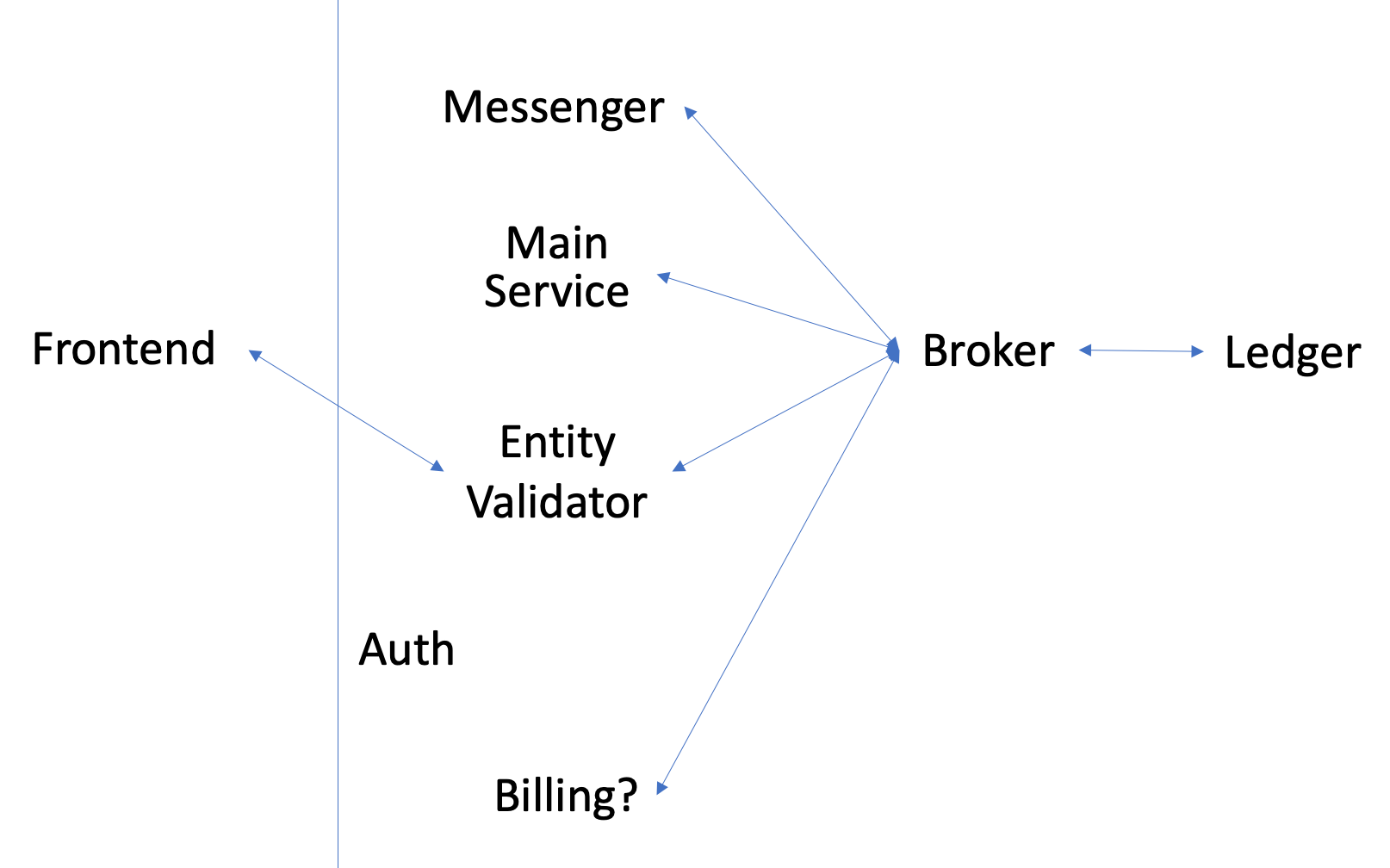
- The
Main Servicetakes the valid rows from the validation errors file and puts it in the DB tables (policies, clients, and carriers).
- Refresh the materialized view.
- Materialized view show policies expiring in the next 12 months. How often should we refresh the mat view? If it needs to be refreshed upon request, use a view. Main Service Mile High Insurance Broker Policies PostgrSQL table
| id | carrier_id | client_id | ... | extras | created_at | updated_at | deleted_at |
|---|---|---|---|---|---|---|---|
| 1 | 613 | 4619 | ... | {'carrier_policy_number': 204666} | 2016-12-31 20:00 | NULL | NULL |
- If the data was inconsistent between brokers and we wanted more structured extras, I would consider using a NoSQL DB like DynamoDB.
- The
Main Servicesends a message to theBrokersaying the data has been stored in the DB and the materialized view has been refreshed. TheMessengerservice andEntity Validatorare subscribed to that topic.
- The messenger service sends a message via email or Slack to interested internal parties and our broker (if they use sftp), saying the process is complete and attaches the validation errors. The
Messengerservice sends a message to the broker saying it sent an email/slack message.
- If the initial request came from the frontend (not sftp or manual drop), send an HTTPS response. The frontend gets the validation errors from s3.
Next Steps: How can we best meet carrier needs? To meet these needs, do we need to add another service or more endpoints to the Main Service? How can they access the materialized views that hold the policies expiring in the next 12 mo?
- The
Entity Validatorservice receives a request from the frontend to update the broker entity config (i.e., the DynamoDB that holds things like the file_headers_map) - The request is validated
- If valid, update the DynamoDB table
- Send a response to the frontend
We’re looking to conduct an initial assessment of the data to determine its quality and completeness and provide feedback to the client about how to proceed. For example, we could choose to accept the data as-is, suggest a program to implement further measures to correct the source data, implement data correction or augmentation on our side, or something else entirely.
Questions:
How would you assess the quality, completeness, and accuracy of this data set? What metrics and dimensions would you review, and what would those tell you?
I feel unqualified to make these decisions, but here's my best solution.
Ingestion failure criteria (no entities are accepted):
- Row count is greater than expected (which could mean there was an unescaped comma). The expected row count is stored in the DynamoDB table.
- Missing expected headers
- Invalid entities exceed the validity threshold. If a file has too many invalid entities, a required field could consistently be the wrong data type (e.g., id is not an int).
Entity rejection criteria (some entities are accepted):
- Use a Pydantic validator to validate the data type, accepted values, and reformat data. Quality/Accuracy:
- Determine the field's data type and the data type the field will be stored in the DB as (e.g., expiration_date is stored as a human-readable datetime). If the data type is incorrect or the entity cannot be cast as that data type, reject the entity.
- Reformat data as needed: strip strings, round floats/ints, combine address fields Completeness:
- Determine required/optional fields (e.g., id is required and company_address_2 is not). If a required field is not present, reject the entity.
- Broker-specific fields can be stored in extras field (e.g., only Mile High Insurance Broker includes the carrier_policy_number). The extras column can be JSONB data stored in an extras column in the DB. Entities are not accepted/rejected based on extras data.
- Do not accept entities with duplicate ids in a file. A policy can have one carrier and one client. A carrier or client can have one policy.
- Do not accept policies that don't have an associated carrier and client
- Do not accept carriers or clients that do not have an associated policy
- Validate dates within a specific range (e.g., don't accept expired policies), validate state names, validate zip codes
After running those assessments, what is your conclusion about the results? Would you feel comfortable proceeding with this data as-is, or would you suggest additional steps to clean or supplement it? Explain what you would do and why. I would ask the broker to correct the data or help us understand why some data is missing. There could be a way to supplement it if we have a better understanding of why things are missing. For example, clients in Major Group 23 might not have an Industry Group; there's only one Industry Group in that Major Group and so it's implied that the Industry Group is 1. The value isn't missing, it was intentionally left blank. If the Industry Group truly is missing, we may also be able to deduce the missing Industry Group from other policies that have the same Major Group, SIC, and Description.
We could add a warning field in addition to our error field in our ingestion errors csv. This could show data that was accepted, but it had missing optional fields, or we supplemented the data. This leads to a bigger question, will the Broker look at or correct the validation errors file?
To discover more supplementation, I would iterate on the process and look at the fields to determine where we can make improvements.
The broker has provided this data by manually exporting three tables from the database of their source system (a SQL database located on their internal network) but would like to automate that process moving forward to reduce manual effort and provide more current data. On the Highwing side, we would like to retain both historical snapshots of the data and a current-state live database with the most recent data for this broker.
Questions:
How would you approach operationalizing the retrieval and loading of this data? Sketch out (in words or a diagram) an architecture.
See Ingestion Process
How would you catalog and store the data?
See Ingestion Process
What operational and security measures would you consider in your design?
- One database per customer (I'm on the fence about this; could use a different schema for each broker)
- Don't send customer data in HTTPS response or SQS messages; keep all of the data in s3
- Encryption in transit (wrapping traffic in SSL) and at rest (Amazon RDS and DynamoDB resources)
- Encrypt DB snapshots and maintain them (in case data is compromised)
- Configure our network to lock down all but exactly the ports/servers we need to be externally available to reduce the possible attack surface.
- Auth system
- Follow a "least permissions" model, where any actor in the system (human or machine) has only those permissions it needs to perform the work it's doing, nothing more.
How would you monitor the quality of the data over the long term?
- Could also have a historical data service I'm stumped on this one. How are you using the historical data? What are the assumptions and limitations of your architecture?
- I made a lot of assumptions, but I don't understand your business needs
- A message broker service like RabbitMQ would be better than SNS messages. A broker service enables routing to workers, doing pub/sub, using topics, but that might not be what we need.
- If something drops along the process, how would a human know to go fix it? I didn't look into error handling as well as I wanted to.
Part 3: Augmentation
After identifying several gaps and duplicates in the data set and discussing them with the broker, they have determined that rectifying those gaps in their source system (mainly for historical data) will not be feasible due to volume. They have asked us to come up with alternative options for augmenting or correcting data using independent sources.
Questions:
How would you approach this problem? What areas of data are most in need of cleanup, and what would you prioritize down? What services/sources/tools would you use? Why would you use that particular set?